優化演算法練習 Leetcode X Valid Anagram
今天來探討 Anagram 字謎的 Easy 演算法練習題目,認識新的 Count Array 計算陣列統計法。
拆解題目
242. Valid Anagram
Given two strings s and t, return true if t is an anagram of s, and false otherwise.
Example 1:
Input: s = “anagram”, t = “nagaram”
Output:true
Example 2:
Input: s = “rat”, t = “car”
Output:false
Constraints:
1 <= s.length, t.length <= 5 * 104s and t consist of lowercase English letters.
解答思考
sort 暴力字母排序法
題目需要將相同小寫英文字母的組成視為 true 排序則不管:例如 car 和 acr、rca、arc 等等就返回 true。
我腦海想到的第一個做法就是暴力解 sort 將 s 和 t 字串按照字母順序排列後相同就表示組成一樣!
但我自己很清楚這個時間的演算效率會是 _log(n log n)_,一定有更好的解法。
1 | /** |
寫起來很簡潔但運算效率要仰賴 a、b 字元的前後比對交換,花費的時間多效率差。
所以今天來多學兩個更好的作法。
Count Array 計數陣列演算法
計數陣列的作法可以理解為 **計數白板(Counting whiteboard)**,把 26 個字母從 a - z 以 ASCII (American Standard Code for Information Interchange,美國標準資訊交換碼) 十進位制的特色來破解題目。
我們來借用一下實作原理需要的 Method charCodeAt 來反推小寫英文的 UTF-18 編碼十進位制: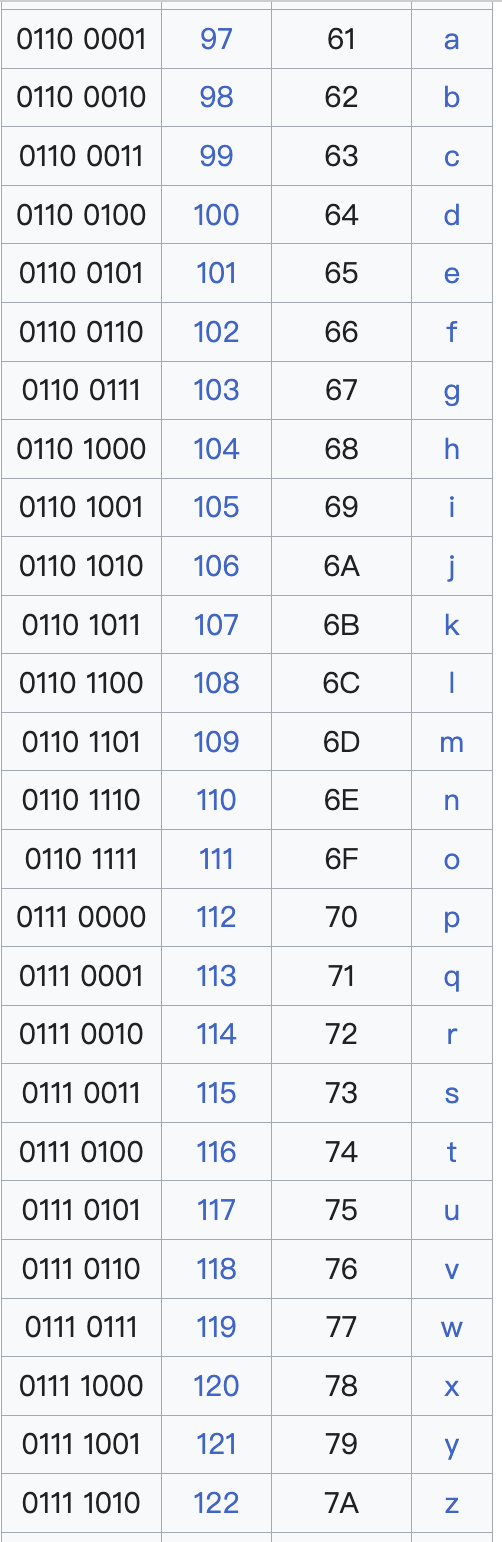
從上圖可以知道小寫字母的 ASCII 十進位制代碼從 a 的數字 97 到 z 的 122,都是按照規則 i++ 的順序排列的,我們可以借用此規則當作陣列的索引值:
1 | 'a'.charCodeAt(0) // 26 |
使用一個固定長度 Array(26) 並且每個所以從 0 計算該字母在 s 字串中出現幾次、並於 t 字串中一一扣除,如若最後該陣列計分板都歸 0 就表示兩個陣列無論在字母還是數量上都相等:
1 | /** |
將每個字母出現在 s 的索引值 value ++; 將每個字母出現在 t 的索引值 value –; 這樣的用意在統計某個英文字母是否在兩個字串出現的頻率相同:例如 a 出現在 s 字串中 n 次、在另一個 t 字串也一定會出現 n 次,用這樣的邏輯來消除每一個字母,若出現負數或正數就表示兩個字串不符合此**字謎(Anagram)**邏輯。
Hashmap 雜湊地圖演算法
是演算法裡的老朋友了,把 s 字串當作字典,並且將出現的次數一一紀錄後,由 t 字串來查詢是否符合字典裡的要求:字母、次數。
1 | /** |
提高效率的小撇步:將 for(let item of arr) 以 for(let i; i < ...) 來取代可以減少背後呼叫 arrSymbol.iterator物件去逐個取得元素,根據裝置 / 瀏覽器略有不同,但通常 for 會快 1.5~2 倍以上。
1 | /** |
取決於公司偏重大量資料下取求速還是易維護,各有所好沒有對錯~~
以上就是這次的解題分享,感謝 ChatGpt 老師 =)